
Web scraping is a very important method for businesses and their platforms in today’s digital world. This method provides automatic collection and analysis of information from any web page. For example, a Google Images API scrapes SERP data from Google Images. However, there are some aspects that developers should pay attention to in web scraping. Chief among these is the conduct of web scraping in accordance with ethical principles and data privacy.
Google Images API, Reverse Google Images API, and many more web scraping APIs follow ethical rules and data privacy. But have you ever thought about what exactly these concepts mean and why they are important? In this article, we will first introduce what data privacy is in web scraping. Then, we’ll touch on the importance of ethical web scraping and talk about the do’s and don’ts of ethical web scraping. Finally, we will introduce a web scraping API that complies with ethical web scraping principles.
Table of Contents
What Is Data Privacy in Web Data Scraping?
Data privacy is a concept that aims to protect the rights and privacy of individuals regarding the collection, storage, processing, and sharing of their personal information. This information about individuals can be the name, location, and contact information of the individual. Web scraping, on the other hand, is the process of automatically collecting information from the target website, and data privacy is of paramount importance in this process.
Data privacy is considered a fundamental human right in many jurisdictions and data protection laws are in place to protect this right. If data privacy is breached in web scraping processes, individuals’ privacy is compromised and their personal information may be misused.
What Is the Importance of the Ethical Web Scraping?
Ethical web scraping is an important method frequently used to access and collect information on the Internet. This method adopts ethical principles such as respect, honesty, and confidentiality in web scraping processes. With ethical web scraping, developers ensure respect for the rights of other website owners, protect data privacy and privacy of data owners, and in addition comply with legal regulations directly. Additionally, it maintains reliability. For these and many more reasons, it is very important for developers to follow ethical principles in their web scraping processes.
Now, we will mention what developers should and do not do in ethical web scraping processes.
Do in Ethical Web Scraping
Knowing the Terms of Use: Developers should know the terms of use and terms of service of the target website they are going to scrape. The target website owner can specify which pages, or directories, web scraping tools can scrape. Compliance with these conditions is essential for an ethical web scraping process.
Follow the Robots.txt File: Developers should review the website’s robots.txt file and abide by the restrictions written in this file. The website owner determines which regions web scraping tools can access via the robots.txt file.
Ensure Data Privacy and Security: Safely store and protect the data you collect. It is important in this regard to take appropriate measures for data security and privacy and to prevent unauthorized access.
Do Not in Ethical Web Scraping
Scraping Data Without Permission: In web scraping processes, it is unethical to scrape data without obtaining permission and consent from data owners. Developers must protect the privacy and rights of data owners.
Do Not Overload the Servers: It is very important not to overload the servers when web scraping. Avoid generating excessive traffic that could damage the website’s servers or data.
Zenserp API: A Web Scraper API that Adheres to Ethical Principles
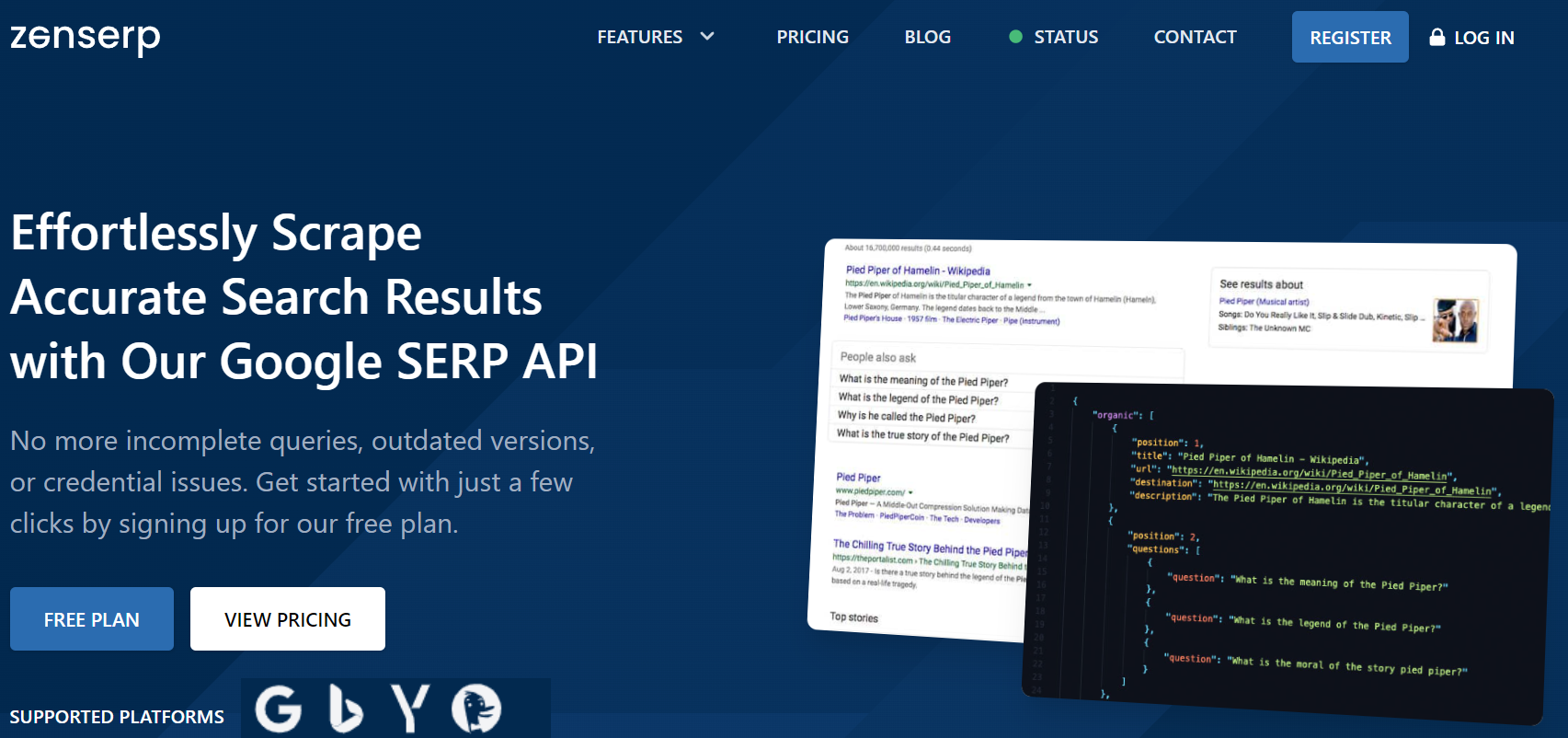
Zenserp API is a web service that provides data scraping to users. This API is a service that provides data with ethical web scraping and data privacy principles.
Zenserp API can extract data on SERP results seamlessly. It supports search engines such as Google, Yandex, Bing, and DuckDuckGo. It also offers Reverse Google Images, the most popular service today. Additionally, it also offers a location-based web scraping service.
With this API, developers can scrape data limited to HTTP requests. It provides users with multiple subscription plans. The first of these plans is the free plan. With the free plan, developers are limited to 50 requests per month.
Conclusion
To sum up, as the popularity of web scraping increases, the considerations about web scraping become more prominent. In particular, ethical web scraping and data privacy are the most important principles to be observed and followed. It is the best method to obtain data with ethical web scraping without damaging the Internet ecosystem.
Discover our web scraper API, and extract data with ethical and data privacy.
FAQs
Q: Why Should Ethical Web Scraping be Done?
A: Users should protect the privacy and rights of data subjects by ethical web scraping. Additionally, ethical web scraping ensures respect for other website owners and does not harm the Internet ecosystem.
Q: What is the Robots.txt File in Websites?
A: Robots.txt is a simple script that tells search engine software which parts of their website to index and which index to scrape. Additionally, it tells web scraping tools which parts can or cannot be scraped data. This file helps the website owner control the behavior of any web data extraction tool and determines what pages, directories, or content web scrapers can scrape from web pages.
Q: Should Web Scrapers Follow Ethical Principles?
A: Yes, they should. The web crawling tools serving in the web scraping industry keep their users away from illegal transactions by complying with ethical principles. Thus, they offer their users a highly secure and seamless extracting data experience.
Q: What are the Don’ts in Ethical Web Scraping Processes?
A: There are certain things that users should not do in ethical web scraping processes. Some of these are as follows:
- Harmful or Offensive Actions
- Using Data Maliciously
- Non-Compliance with Legal Regulations