
The advent of web scraping has brought about a revolution in technology. In particular, it has had great importance in the development of algorithms developed in the field of artificial intelligence. Web scraping has provided the substance that will directly bring these apps to life. Data.
Web scraping is currently the easiest and fastest way to extract data from the internet. Manually collecting data from the Internet is a very laborious and time-consuming process. You can perform this process automatically from target websites with data scraping tools.
Web data scraping has also evolved a lot since its inception. It has become quite easy to extract data from many websites such as Google, Yandex, YouTube Search, and Bing which are difficult to scrape these days. There are so many apps and projects that are growing and developing today by scraping data from Google Search Results. In this article, we will talk about how to scrape Google Search Results without any limits.
Table of Contents
Scraping with Python
It is possible to scrape Google Search Results with a Python code that we will write ourselves, but this method is not preferred. The main reason for this is that we will need to make some configurations in order not to be blocked by Google and not to enter the blacklist. Otherwise, the scraping will be detected by Google in the future and our program will be blocked by Google. These configurations should include setting up a large proxy pool, automatic IP change, etc.
Let’s simply create a Python file to run our Python codes that will scrape the Google Search Result. Then, let’s download the following packages to our application via the terminal.
pip install bs4 pip install requests
Now let’s paste the following codes into the Python file we created.
import requests import bs4 search_url = 'https://google.com/search?q=pikachu' search_results= requests.get(search_url) b_soup = bs4.BeautifulSoup(web_results.text, "html.parser") h3_heading = b_soup .find_all('h3') for head in h3_heading: print(head.getText())
When we run this code, we will have scraped results for the word ‘Pikachu’ in Google Search.
Scraping with Zenserp Playground
Another popular method of scraping Google Search Results would be to effortlessly scrape with the playground provided by Zenserp. This method is a frequently preferred method, but this method does not save much time. But with this method, you will not have any blocking or blacklist concerns.
We can access the playground provided by the Zenserp API here.
For example, we have access to much more information, especially the web scraping results of ‘Pied Piper’, as follows.
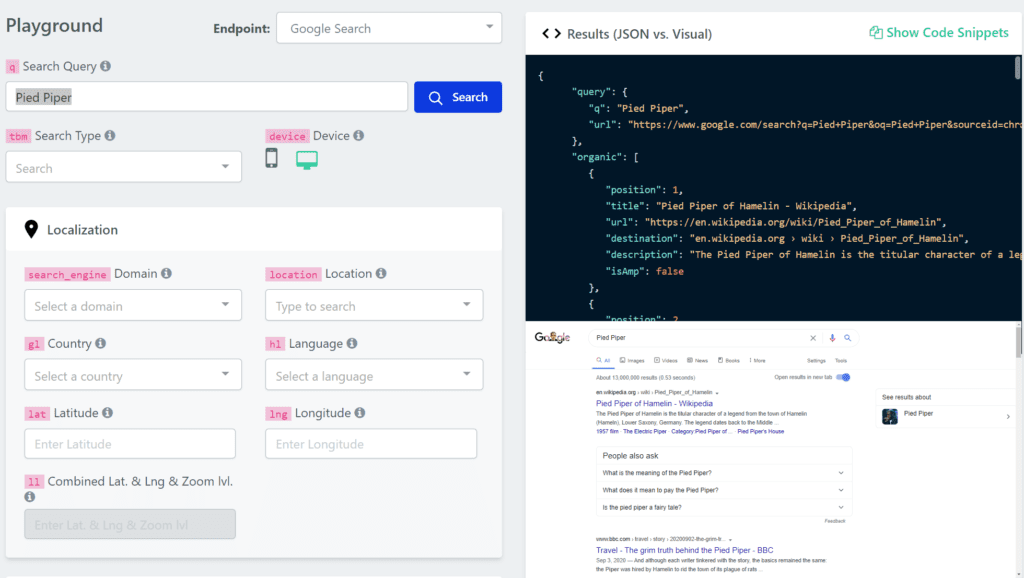
Scraping with Zenserp API
The most popular and fastest way to scrape Google Search Results is with web scraping API. Zenserp API is the most preferred Google Search Result scraping API today. Zenserp API provides its users with a large proxy pool and automatically rotated IP service. The main reason for its popularity is that it scrapes many websites in seconds, such as YouTube, Google Images, Google News, Google Video, Google Search, Yandex, and Google Trends, which are difficult to scrape.
Thanks to its technological infrastructure, it can be integrated into applications quite simply in just a few steps. It has integration into almost every programming language.
To try the Zenserp API, first of all, let’s register by choosing a package, especially the free package, and obtain an API key.
Then, let’s request the following endpoint from the browser with the API key you obtained.
https://app.zenserp.com/playground/search?q=SpongeBob&apikey={YOUR_API_KEY}
When we request this API from the browser, we get the following results.
{ "query": { "q": "pikachu", "apikey": "700cebf0-cbf4-11ec-babe-231cd33159ce", "url": "https:\/\/www.google.com\/search?q=pikachu&oq=pikachu&hl=en&gl=us&sourceid=chrome&ie=UTF-8" }, "knowledge_graph": [ { "title": "Pikachu", "subtitle": "Pokemon species", "image": "data:image\/gif;base64,R0lGODlhAQABAIAAAP\/\/\/\/\/\/\/yH5BAEKAAEALAAAAAABAAEAAAICTAEAOw==", "description": "DescriptionPikachu is a fictional species in the Pok\u00e9mon media franchise. Designed by Atsuko Nishida and Ken Sugimori, Pikachu first appeared in the 1996 Japanese video games Pok\u00e9mon Red and Green created by Game Freak and Nintendo, which were released outside of Japan in 1998 as Pok\u00e9mon Red and Blue. Wikipedia", "shared_height": "1\u2032 4\u2033", "shared_weight": "13\u00a0lbs", "shared_evolves_to": "Raichu", "shared_evolves_from": "Pichu", "shared_weakness": "Ground", "shared_abilities": "Static", "shared_category": "Mouse", "okra\/answer_panel\/_evolution_level": "Evolution levelSearch for: pikachu evolution level", "okra\/answer_panel\/_moveset": "MovesetSearch for: moveset for pikachu", "downwards": [ { "name": "Ash Ketchum", "link": "\/search?newwindow=1&hl=en&gl=us&q=Ash+Ketchum&stick=H4sIAAAAAAAAAONgFuLUz9U3MMwrKk9SAjONknLMCrVEspOt9JPzc3Pz86xS8svzyhOLUopXMQq7ZSaXZObnJeY4ZyQWJSaXpBYVL2LldizOUPBOLUnOKM3dwcoIABUGYAhVAAAA&sa=X&ved=2ahUKEwiCmuTUqNj7AhUZ6CoKHc5pDI0QxA16BAhsEAM", "image": "data:image\/gif;base64,R0lGODlhAQABAIAAAP\/\/\/\/\/\/\/yH5BAEKAAEALAAAAAABAAEAAAICTAEAOw==" }, { "name": "Ash's Pikachu", "link": "\/search?newwindow=1&hl=en&gl=us&q=Ash%27s+Pikachu&stick=H4sIAAAAAAAAAONgFuLUz9U3MMwrKk9S4tZP1zc0MkpKKy4o1hLJTrbST87Pzc3Ps0rJL88rTyxKKV7FKOyWmVySmZ-XmOOckViUmFySWlS8iJXXsThDvVghIDM7MTmjdAcrIwBkqQfDWQAAAA&sa=X&ved=2ahUKEwiCmuTUqNj7AhUZ6CoKHc5pDI0QxA16BAhsEAU", "image": "data:image\/gif;base64,R0lGODlhAQABAIAAAP\/\/\/\/\/\/\/yH5BAEKAAEALAAAAAABAAEAAAICTAEAOw==" }, { "name": "Brock", "link": "\/search?newwindow=1&hl=en&gl=us&q=Brock+(Pok%C3%A9mon)&stick=H4sIAAAAAAAAAONgFuLUz9U3MMwrKk9SAjONyk0rk7REspOt9JPzc3Pz86xS8svzyhOLUopXMQq7ZSaXZObnJeY4ZyQWJSaXpBYVL2IVcCrKT85W0AjIzz68EqhDcwcrIwBsDucpWgAAAA&sa=X&ved=2ahUKEwiCmuTUqNj7AhUZ6CoKHc5pDI0QxA16BAhsEAc", "image": "data:image\/gif;base64,R0lGODlhAQABAIAAAP\/\/\/\/\/\/\/yH5BAEKAAEALAAAAAABAAEAAAICTAEAOw==" }, { "name": "Professor Samuel Oak", "link": "\/search?newwindow=1&hl=en&gl=us&q=Professor+Samuel+Oak&stick=H4sIAAAAAAAAAONgFuLUz9U3MMwrKk9S4gIx89ILDM0stESyk630k_Nzc_PzrFLyy_PKE4tSilcxCrtlJpdk5ucl5jhnJBYlJpekFhUvYhUJKMpPSy0uzi9SCE7MLU3NUfBPzN7ByggAvp9bWF8AAAA&sa=X&ved=2ahUKEwiCmuTUqNj7AhUZ6CoKHc5pDI0QxA16BAhsEAk", "image": "data:image\/gif;base64,R0lGODlhAQABAIAAAP\/\/\/\/\/\/\/yH5BAEKAAEALAAAAAABAAEAAAICTAEAOw==" } ] } ], "organic": [ { "position": 1, "title": "Pikachu (Pok\u00e9mon) - Bulbapedia, the community-driven ...", "url": "https:\/\/bulbapedia.bulbagarden.net\/wiki\/Pikachu_(Pok%C3%A9mon)", "destination": "https:\/\/bulbapedia.bulbagarden.net \u203a wiki \u203a Pikachu_(Pok...", "description": "Pikachu is a short, chubby rodent Pok\u00e9mon. It is covered in yellow fur with two horizontal brown stripes on its back. It has a small mouth, long,\u00a0...", "isAmp": false }, [...] } ], "related_searches": [ { "title": "pikachu movie", "url": "https:\/\/www.google.com\/search?newwindow=1&hl=en&gl=us&q=Pikachu+movie&sa=X&ved=2ahUKEwiCmuTUqNj7AhUZ6CoKHc5pDI0Q1QJ6BAheEAE" }, { "title": "pikachu show", "url": "https:\/\/www.google.com\/search?newwindow=1&hl=en&gl=us&q=Pikachu+show&sa=X&ved=2ahUKEwiCmuTUqNj7AhUZ6CoKHc5pDI0Q1QJ6BAhfEAE" }, { "title": "pikachu song", "url": "https:\/\/www.google.com\/search?newwindow=1&hl=en&gl=us&q=Pikachu+song&sa=X&ved=2ahUKEwiCmuTUqNj7AhUZ6CoKHc5pDI0Q1QJ6BAhcEAE" }, { "title": "pikachu costume", "url": "https:\/\/www.google.com\/search?newwindow=1&hl=en&gl=us&q=Pikachu+Costume&sa=X&ved=2ahUKEwiCmuTUqNj7AhUZ6CoKHc5pDI0Q1QJ6BAhdEAE" } ], "number_of_results": 112000000, "pagination": { "current_page": null, "next_page": null, "previous_page": null, "pages": [ ] }, "html": "nohtmlsupported" }
Conclusion
We have mentioned 3 ways to successfully scrape google search API python without any limits. Among these ways, the most preferred way is to use the Google Search Result API. If you want to scrape Google, which is difficult to scrape quickly and automatically without any limits with the Google Search API, explore the Zenserp API.